
Redis란?
Redis는 고성능의 키-값(key-value) 저장소로, 거대한 맵(Map) 데이터 저장소형태를 가지고 데이터를 메모리에 저장하여 빠른 읽기와 쓰기를 지원하는 오픈 소스 기반의 비관계형 데이터베이스 관리 시스템이다.
Redis의 특징
1. 고성능
RDBS(Relational Database Management System)는 디스크 기반의 저장 방식을 사용한다.
디스크 기반의 저장 방식은 메모리 저장 방식에 비해 데이터를 오래 보관할 수 있다는 장점이 있지만,
메모리에 있는 데이터를 조회하는 방식에 비해 처리 속도가 느리다는 단점이 있다.
반면 Redis는 데이터를 디스크에 쓰는 구조가 아니라, 메모리에서 데이터를 처리하기 때문에 속도가 매우 빠르다.
또한 Redis도 필요시 디스크에 스냅샷 저장이나 AOF(Append Only File)기록을 통해 영속성을 지원한다.
2. Key- Value 방식의 단순한 데이터 구조
Redis는 Key-Value 구조의 데이터 구조를 사용하기 때문에 SQL처럼 복잡한 쿼리 없이도 데이터 조작이 가능하며, 다양한 자료구조(Hash, List, Set 등도 지원)로 단순하면서도 유연합니다.
3. Single Thread 구조
Redis는 모든 클라이언트 요청 처리를 단일 스레드에서 수행한다.
이 말은 클라이언트의 동시 요청이 들어오더라도 Redis가 이 요청들을 순차적으로 하나씩 처리한다는 의미이다.
이럴경우 트랜잭션의 일관성이 보장되어 동시성 문제가 발생하는 것을 방지할 수 있다.
사용 예시
1. 캐싱 시스템 (Cache)
• 자주 조회되는 데이터를 메모리에 저장해 원본 데이터베이스의 부하를 줄이고 빠른 응답 속도 제공
• 예: 상품 정보, 사용자 프로필, 페이지 콘텐츠 등
• TTL(만료시간) 설정으로 캐시 데이터를 자동 관리
2. 세션 저장소 (Session Store)
• 사용자 로그인 세션 데이터를 Redis에 저장하여 빠른 인증과 세션 관리 가능
• 여러 서버가 같은 Redis에 세션 정보 저장해 로드밸런싱 및 분산 환경에서 효과적
• Refresh Token을 Redis에 저장하여 로그인 상태를 지속적으로 유지하고 인증 관리 가능
3. 리더보드(순위 집계)
• Redis의 Sorted Set 자료구조를 이용해 점수 기반의 순위 계산 및 조회
• 예: 게임 점수 순위, 활동량 랭킹 등
• 자동 정렬과 빠른 조회 지원
4. 실시간 분석 및 통계
• 실시간 트래픽 모니터링, 사용자 활동 집계, 이상 징후 감지 등
• Redis의 다양한 자료구조(Hash, Sorted Set 등)을 활용해 빠른 집계 및 분석 가능
5. 메시지 큐 및 Pub/Sub 시스템
• 실시간 메시지 전송 및 구독 기능 지원
• 채팅 애플리케이션, 푸시 알림, 이벤트 스트리밍 등에 활용 가능
Redis 자료구조
기본적으로 Redis는 0~15까지 16개의 데이터베이스를 제공한다.
최초 접속시 default값인 0번 데이터베이스로 이동하고, select 명령어를 이용해 데이터베이스를 선택 가능하다.
127.0.0.1:6379> select 10
OK
127.0.0.1:6379[10]> select 0
OK1. String 자료구조
String 자료구조는 Redis에서 가장 기본적이고 단순한 데이터 타입이다.
하나의 Key에 하나의 Value를 저장하는 단일 값 저장 방식이다.
키에 값을 설정할때는 SET 명령어를 사용한다.
127.0.0.1:6379> set user:email:1 yang@naver.com
OK
127.0.0.1:6379> keys *
1) "user:email:1"
그리고 Key의 Value를 가져올때는 GET을 사용할 수 있다.
127.0.0.1:6379> get user:email:1
"yang@naver.com"
만약 Key에 대한 Value가 존재 하는데, 동일한 Key에 대해서 SET을 통해 다른 Value를 설정하면 기존에 설정한 Value를 대신해 새로운 Value가 덮어 씌워지게 된다.
TTL(Time To Live)값 설정
Redis는 Key-Value에 대해서 Key 유지(만료) 시간을 셋팅할 수 있다.
'EX 초단위 시간' 형식으로 지정 가능한다.
127.0.0.1:6379> set user:email:3 yang3@naver.com ex 10
OK
127.0.0.1:6379> keys *
1) "user:email:2"
2) "user:email:1"
3) "user:email:3"
#10초 후
127.0.0.1:6379> keys *
1) "user:email:2"
2) "user:email:1"
캐싱처리
Redis의 String 자료구조는 캐싱 처리에 유용하게 사용될 수 있다.
여기서 캐싱이란 데이터를 한 번 받아오거나 계산한 후, 그 데이터를 더 가까운 곳(예 : 메모리나 임시 저장소)에 임시로 저장해 두었다가, 나중에 다시 필요할 때 빠르게 불러와 사용하는 기술을 의미한다.
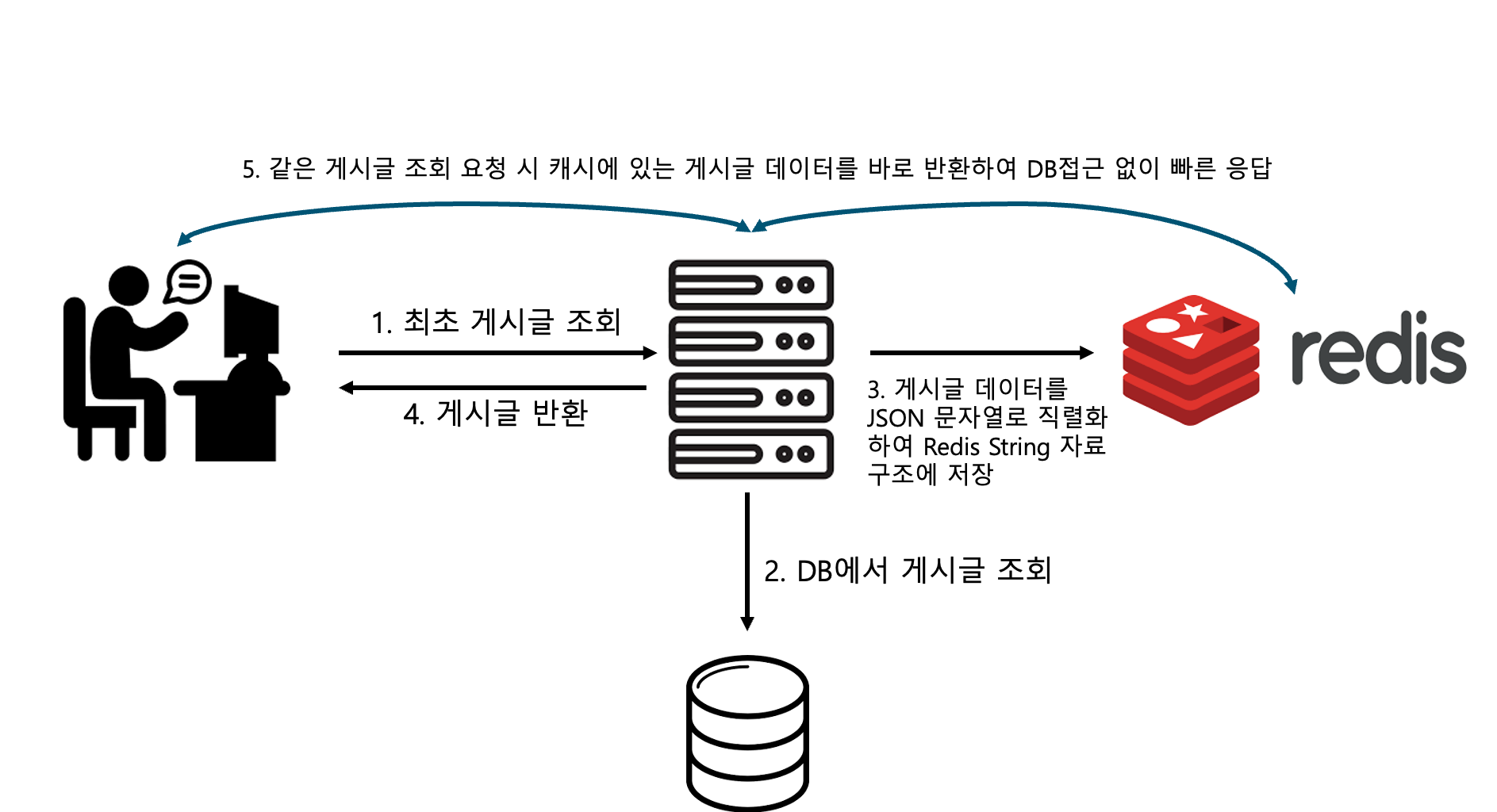
게시글 조회를 예시로 들면,
최초에 게시글을 조회하게 되면 DB에 접근하여 게시글을 조회하고 게시글 데이터를 캐싱하기 위해 JSON 문자열로 직렬화 하여 Redis에 저장한다.
이후 같은 요청을 하게되면 Redis에 저장되어있는 데이터를 바로 반환하기 때문에 처리 속도를 높이면서 서버 부하도 줄일 수 있다.
2. List 자료구조
Redis에서 List는 일반적인 프로그래밍 언어에서의 List와 다르게 데크(deque) 자료구조를 사용한다.
데크는 양쪽 끝에서 삽입, 삭제를 수행할 수 있는 자료구조를 의미한다.
(Redis의 List는 데크 구조를 사용하므로 데이터를 중간에 삽입하는 것은 불가능하다.)

List에 데이터를 추가 및 조회하는 방법은 다음과 같다.
1. lpush : 데이터를 왼쪽에 삽입
127.0.0.1:6379> lpush yangwoohyeon yang1
(integer) 1
2. rpush : 데이터를 오른쪽에 삽입
127.0.0.1:6379> rpush yangwoohyeon yang3
(integer) 3
3. lpop : 데이터를 왼쪽에서 꺼내기
4. rpop : 데이터를 오른쪽에서 꺼내기
5. lrange : list 조회 (0은 시작점, -1은 list의 끝자리 의미)
127.0.0.1:6379> lrange yangwoohyeon 0 -1
1) "yang2"
2) "yang1"
3) "yang3"
6. llen : 데이터 개수 조회
127.0.0.1:6379> llen yangwoohyeon
(integer) 1
7. expire : TTL적용
127.0.0.1:6379> expire yangwoohyeon 10
(integer) 1
List 자료구조 활용
사용자의 최근 활동 내역 (예 : 최근 본 상품, 최근 검색어 등등)을 일정 개수만큼 저장하는데 사용할 수 있다.
3. Set 자료구조
Set은 순서가 없고 중복이 없는 자료구조이다.
주요 명령어
1. sadd : 집합에 값 추가
127.0.0.1:6379> sadd memberlist member1
(integer) 1
2. scard : Set맴버 개수 조회
127.0.0.1:6379> scard memberlist
(integer) 2
3. sismember : 특정 맴버가 Set안에 있는지 존재여부 확인(있으면 1, 없으면 0)
127.0.0.1:6379> sismember memberlist member1
(integer) 1
4. srem : Set에서 맴버 삭제
127.0.0.1:6379> srem memberlist member2
(integer) 1
Set 자료구조 활용
SNS의 게시글에 대한 '좋아요'기능을 살펴보면 한 사용자가 한 게시글에 대해서 한번만 좋아요를 누를 수 있고, 좋아요를 누른지에 대한 여부도 불러올 필요가 있다.
이러한 기능에 Set 자료구조가 특화되어 있다고 볼 수 있다.
좋아요를 누를때 Set에 사용자ID를 함께 추가하고 좋아요 여부를 'sismember'로 체크하여 불러올 수 있다.
그리고 기존에 좋아요를 누른 사용자가 좋아요를 한번 더 누르더라도 Set은 중복을 허용하지 않기 때문에 문제될게 없다.
4. zset 자료구조
ZSET(Sorted Set)은 각 원소에 점수(score)를 부여하여 자동으로 정렬되는, 유니크한 값들의 집합 자료구조이다.
주요 명령어
1. zadd : 맴버-점수 쌍 추가
127.0.0.1:6379> zadd memberlist 3 member1
(integer) 1
127.0.0.1:6379> zadd memberlist 4 member2
(integer) 1
127.0.0.1:6379> zadd memberlist 1 member3
(integer) 1
127.0.0.1:6379> zadd memberlist 2 member4
2. zrange : Score 기준으로 오름차순 정렬
127.0.0.1:6379> zrange memberlist 0 -1
1) "member3"
2) "member4"
3) "member1"
4) "member2"
3. zrevrange : Score 기준으로 내림차순 정렬
127.0.0.1:6379> zrevrange memberlist 0 -1
1) "member2"
2) "member1"
3) "member4"
4) "member3"
4. zrem : zset 맴버 삭제
5. zrank : 특정 맴버가 몇번째(index 기준) 순서인지 출력
127.0.0.1:6379> zrank memberlist member1
(integer) 1
ZSET 자료구조 활용
최근 본 상품 목록을 저장하는 기능을 예시로 들면,
조회한 시간을 기준으로 정렬하여 중복 없는 최근 본 상품 목록 조회에 사용할 수 있다.
최근 본 상품이나, 주식 가격과 같이 변화가 많고 임시적이며 빠른 접근이 필요한 데이터는 Redis에 저장하는 것이 성능과 운영 측면에서 더 효율적이므로 Redis 활용이 권장된다.
5. Hash 자료구조
Hash는 Value값이 map 형태인 자료구조이다.
아래 형식과 같이 필드와 값의 쌍을 저장하며, 이러한 형식은 객체 형식의 데이터를 캐싱할때 효율적이다.
- name: "Laptop"
- brand: "Apple"
- price: "1500"
- stock: "50"
주요 명령어
1. hset : 필드, 값 데이터 저장
127.0.0.1:6379> hset author:info:1 name hong email hong@naver.com age 30
(integer) 3
2. hget : 특정값 조회
127.0.0.1:6379> hget author:info:1 name
"hong"
3. hgetall : 모든 객체값 조회
127.0.0.1:6379> hgetall author:info:1
1) "name"
2) "hong"
3) "email"
4) "hong@naver.com"
5) "age"
6) "30"
4. hincrby : 필드값을 정수만큼 증가
127.0.0.1:6379> hincrby author:info:1 age 3
(integer) 33
127.0.0.1:6379> hgetall author:info:1
1) "name"
2) "kim"
3) "email"
4) "hong@naver.com"
5) "age"
6) "33"
Hash값은 빈번하게 변경될 가능성이 있는 객체 형식의 데이터를 캐싱할때 효율적이다.
만약 JSON 형식의 문자열로 캐싱된 데이터를 수정해야하는 경우, 일일이 파싱 후 모든 값을 다시 셋팅해야하는 비효율이 존재하는데,
Hash는 특정 요소값만을 변경하기에 용이하기 때문에 비교적 효율적이라고 볼 수 있다.
'BackEnd > Redis' 카테고리의 다른 글
| [Redis] 캐싱을 이용한 간단한 성능 개선 테스트(Apache JMeter) (0) | 2025.08.25 |
|---|---|
| Spring Boot + Redis를 활용한 Refresh Token 기능 구현 (0) | 2025.08.24 |
| Redis DB서버 구성 (0) | 2025.08.22 |